



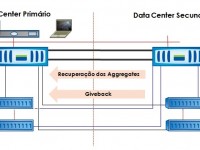
Esse artigo mostra as etapas necessárias para retorno operacional do site primário em uma configuração de MetroCluster após o teste de desastre e virada para o site secundário.
Esse artigo aborda o retorno da operação para o site primário após o DR. Para correto entendimento deste procedimento, usar como referência o artigo anterior que trata do teste de DR:MetroCluster de A a Z (11 de 12): Teste de Disaster Recovery.
Após os problemas que afetaram a queda de todo o site principal terem sido resolvidos, é possível realizar o retorno da operação para o site principal. Porém, há uma sequência específica de verificação e retorno da operação para evitar perda de dados. A sequência está descrita a seguir com exemplos dos logs dos equipamentos do laboratório do Agility Tech Center.
Passos para o Retorno do Teste de Disaster Recovery
1. Religar a força das shelves do lado A, mantendo a controladora ATC-NAP-A desligada até que seja indicado nos passos a seguir.
2. Os logs a seguir (resumidos) mostram o momento em que o ATC-NAP-B percebe o retorno das shelves do lado A (inclusive há o alerta sobre o fsid estar sendo mantido pela opção podendo causar perda de dados). É importante observar também que os aggregates que retornam das falha são renomeados para evitar conflito e são colocados em modo offline para que possam ser trazidos online manualmente após a verificação:
TC-NAP-B(takeover)> Fri Sep 20 10:42:32 BRT [ATC-NAP-B:sas.adapter.online:info]: SAS adapter 4d is now online.
Fri Sep 20 10:42:38 BRT [ATC-NAP-B:sas.adapter.online:info]: SAS adapter 4b is now online.
ATC-NAP-B(takeover)> Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.assim.tree.dupName:notice]: Duplicate aggregate names found, an instance of partner:AGGR_BACKEND_A is being renamed to partner:AGGR_BACKEND_A(1).
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.assim.tree.dupName:notice]: Duplicate aggregate names found, an instance of partner:AGGR_MC_A is being renamed to partner:AGGR_MC_A(1).
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.assim.tree.dupFsid:ALERT]: Aggregate partner:AGGR_MC_A(1) and aggregate partner:AGGR_MC_A have the same FSID (0x5f496f1d). This can lead to data corruption. Please contact NetApp Global Services.
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.assim.tree.offline:error]: Taking aggregate partner:AGGR_MC_A(1) offline due to a duplicate FSID.
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.assim.tree.dupFsid:ALERT]: Aggregate partner:AGGR_BACKEND_A(1) and aggregate partner:AGGR_BACKEND_A have the same FSID (0x17d45388). This can lead to data corruption. Please contact NetApp Global Services.
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.assim.tree.offline:error]: Taking aggregate partner:AGGR_BACKEND_A(1) offline due to a duplicate FSID.
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.vol.mirror.degraded:error]: Aggregate partner:AGGR_MC_A(1) is mirrored and one plex has failed. It is no longer protected by mirroring.
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:callhome.syncm.plex:CRITICAL]: Call home for SYNCMIRROR PLEX FAILED
Fri Sep 20 10:43:09 BRT [ATC-NAP-B:raid.mirror.vote.outOfDate:error]: Aggregate partner:AGGR_MC_A(1) has been detected as out-of-date and is being marked offline.
3. No ATC-NAP-B, validar que é possível acessar as shelves do lado A através do comando aggr status -r. A saída a seguir encontra-se resumida e mostra o ATC-NAP-B acessando os discos remotos da shelf 1 (a shelf 2, apesar de também estar no rack A pertence a outro contexto de MetroCluster do laboratório que não faz parte desta demonstração e portanto foi suprimida da saída):
ATC-NAP-B(takeover)> aggr status -r
(saída resumida)
Partner disks
RAID DiskDevice HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
————— ————- —- —- —- —– ————– ————–
partner 4d.01.224d 1 22 SA:B 0 SAS 10000 418000/856064000 429247/879097968
partner 4d.01.234d 1 23 SA:B 0 SAS 10000 418000/856064000 429247/879097968
partner 4d.01.214d 1 21 SA:B 0 SAS 10000 418000/856064000 429247/879097968
partner 4d.01.204d 1 20 SA:B 0 SAS 10000 418000/856064000 429247/879097968
partner 4d.01.104d 1 10 SA:B 0 SAS 10000 418000/856064000 429247/879097968
saída resumida
4. Entrar no nó ATC-NAP-A emulado com o comando partner:
ATC-NAP-B(takeover)> partner
Login to partner shell: ATC-NAP-A
ATC-NAP-A/ATC-NAP-B> Fri Sep 20 10:44:59 BRT [ATC-NAP-B:cf.partner.login:info]: Login to partner shell: ATC-NAP-A
5. Através do comando aggr status -r, verificar no nó emulado quais aggregates estão do lado do site que falhou (estes estarão com status out-of-date e failed state e quais estão no site sobrevivente (status online). A saída a seguir está resumida:
ATC-NAP-A/ATC-NAP-B> aggr status -r
Aggregate AGGR_MC_A (online, raid_dp) (block checksums)
Plex /AGGR_MC_A/plex1 (online, normal, active, pool1)
RAID group /AGGR_MC_A/plex1/rg0 (normal, block checksums)
RAID DiskDevice HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
————— ————- —- —- —- —– ————– ————–
dparity 4c.04.204c 4 20 SA:B 1 SAS 10000 418000/856064000 429247/879097968
parity 4c.04.214c 4 21 SA:B 1 SAS 10000 418000/856064000 429247/879097968
data 4c.04.224c 4 22 SA:B 1 SAS 10000 418000/856064000 429247/879097968
data 4c.04.234c 4 23 SA:B 1 SAS 10000 418000/856064000 429247/879097968
Aggregate AGGR_MC_A(1) (failed, raid_dp, out-of-date) (block checksums)
Plex /AGGR_MC_A(1)/plex0 (offline, normal, out-of-date)
RAID group /AGGR_MC_A(1)/plex0/rg0 (normal, block checksums)
RAID DiskDevice HA SHELF BAY CHAN Pool Type RPM Used (MB/blks) Phys (MB/blks)
————— ————- —- —- —- —– ————– ————–
dparity 4d.01.204d 1 20 SA:B 0 SAS 10000 418000/856064000 429247/879097968
parity 4d.01.214d 1 21 SA:B 0 SAS 10000 418000/856064000 429247/879097968
data 4d.01.224d 1 22 SA:B 0 SAS 10000 418000/856064000 429247/879097968
data 4d.01.234d 1 23 SA:B 0 SAS 10000 418000/856064000 429247/879097968
Plex /AGGR_MC_A(1)/plex1 (offline, failed, out-of-date)
6. IMPORTANTE: Se os aggregates do lado que falhou estiverem online, colocá-los em modo offline antes de executar o passo 7 através do comando a seguir no nó emulado:
ATC-NAP-A/ATC-NAP-B> aggr offline nome_do_aggregate
7. Recriar os espelhamentos para cada aggregate cujo espelhamento foi interrompido através do seguinte comando (no nó emulado):
ATC-NAP-A/ATC-NAP-B> aggr mirror nome_aggregate_sobrevivente -v nome_aggregate_em_falha
No caso do laboratório, de acordo com a saída no passo 5, o comando seria:
ATC-NAP-A/ATC-NAP-B> aggr mirror AGGR_MC_A -v AGGR_MC_A(1)
8. Retornar à controladora sobrevivente com o comando partner e aguardar o final da recomputação do espelhamento.
9. Ligar a controladora que falhou (ATC-NAP-A) e aguardar o reestabelecimento da interconexão de HA e realizar o giveback a partir do comando cf giveback no ATC-NAP-B para retornar a operação para o ATC-NAP-A.
10. Realizar a verificação do status do HA através do comando cf status em ambas as controladoras, assim como a operação do MetroCluster e o estado dos aggregates com os comandos aggr status e sysconfig -r, dentre outros demonstrados anteriormente no artigo MetroCluster de A a Z (7 de 12): Verificação do Ambiente de HA.
Primeiro artigo da série: MetroCluster de A a Z (1 de 12): Conceito
Referências
Esta série de artigos utiliza como referências testes realizados no laboratório do Agility Tech Center e os seguintes documentos da Netapp:
- System Administration Guide for 7-Mode (versão 8.2 do Data ONTAP)
- High Availability and MetroCluster Configuration Guide for 7-Mode (versão 8.2 do Data ONTAP)
- Network Management Guide For 7-Mode (versão 8.2 do Data ONTAP)
- Best Practices for MetroCluster Design and Implementation (TR-3548)